I need to set the stage here because I cannot in good conscience talk about data protection without first acknowledging that Tom Hollingsworth opened this session with a full WWE-style announcer intro for the Commvault presenters. Ring announcer voice. The whole bit. Commvault's RSAC booth was a wrestling ring. "The ResOps Rumble." Villain names like "Misconfig Misfit" and "Identity Impostor." Michael Fasulo took the mic after and opened with "Man, that's gonna be a really hard act to follow," which is the most composed reaction anyone could have had to what just happened.
All of us delegates were dying. It also immediately told me this was not going to be a typical vendor session.
I was right about that. Just not in the way I expected.
This was a Tech Field Day Extra session at RSAC 2026, and honestly, when I sat down I wasn't sure what I was going to get. A recovering CISO told a story that grounded the whole talk in present-day reality, the product team showed actual tech, and I ended up asking three questions that told me more about where data protection is headed than any slide could.
A Recovering CISO and a 284-Day Nightmare
Chris Bevel introduced himself as a "recovering CISO," which got a laugh, but he meant it. He said joining Commvault meant he could go on a July 4th vacation without waiting for the phone to ring about someone clicking a link. Can I get a guide on how to do this too?
But the story that landed hardest: in 2021, Bevel got a personal letter from the Conti ransomware group while serving as incident commander for another organization. That org took 284 days to fully recover. Not days to get some systems back. Days to fully recover. Six months later, they got hit again. They never verified whether the data they restored was clean.
This was a cash cow for a Major League Baseball organization's owner. Real resources. Real team. Still couldn't answer the most basic question: can we trust what we're restoring?
That's the thesis of the entire session, and the thesis of this article. Disaster recovery is not cyber recovery. A hurricane doesn't encrypt your Active Directory. Ransomware does. And if your recovery plan doesn't account for that difference, you're reloading the threat.
The Hawaii Problem
Bevel told another story that stuck with me. He worked with an organization in Hawaii that could do disaster recovery better than anyone. He threw every tabletop exercise he could think of at them. Kitchen sink. They nailed it every time.
But when the conversation shifted to cyber recovery, how do you recover cleanly? How do you know the data you're restoring hasn't been sitting there compromised for weeks? That confidence evaporated.
DR assumes your data is good and you just need to put it back. Cyber recovery assumes your data might be the problem. That's a fundamentally different starting point, and most organizations haven't made that shift yet.
Commvault's "ResOps"
Commvault is calling their approach ResOps, short for Resilience Operations. Four principles:
- Assume compromise
- Expect loss of trust
- Design for clean recovery
- Automate where humans can't scale
On paper, that reads like any modern security framework. What made it interesting here was watching how the actual product maps to those principles. This wasn't slideware with four bullets. They demo'd it, live.
And the tech is doing more than I expected from a company I'd mentally filed under "backup."
Out-of-Band Detection (In Your Backups)
The piece that shifted my thinking was how Commvault is scanning backup data for threats, not just protecting it. They've built a layered detection engine that runs across your backup repository:
- Signature-based scanning
- ML models trained on real ransomware samples to detect encryption
- Hash lookups against known IOCs
- YARA rule support (bring your own or import from threat intel platforms)
- A deep scanning engine for polymorphic threats and zero-days
The demo showed David Cunningham importing LockBit hashes from Google Threat Intelligence directly into a backup plan, then running a full historical threat hunt across every backup for that resource. Your SOC hands you a list of IOCs on a Tuesday afternoon? Import them, scan backwards through your entire backup history, find out if you've been sitting on compromised data for weeks.
They also showed signal correlation across layers. Anomalies alone get flagged as moderate risk. Combine an anomaly with a partner signal from CrowdStrike or a detected hash match, and it escalates to high or critical. The distinction matters: it's not "something changed," it's "something changed, here's why, and here's our confidence level."
Michael mentioned they've had customers whose EDR missed something that Commvault's backup scanning caught. That's a sentence I did not expect to write about a company I had categorized as a backup vendor.
Three Questions
I asked three questions during the session. The answers are what convinced me Commvault is actually repositioning, not bolting security features onto a backup product.
Question 1: Where are you getting the data insights?
They showed Satori-powered data discovery and classification, finding PII, secrets, passwords across structured and unstructured data. I wanted to know: is this pulling from data I'm already protecting, or do I have to deploy something new as an overlay across my environment?
Both, your choice. You can sweep live production data directly, or run it against your backups. Some customers don't want agents touching production. Others don't want to move massive datasets for classification. Commvault supports either path.

The DSPM dashboard. Scan coverage, violation severity, risk scores, and sensitive data exposure across resources, all in one view.
That optionality is what separates a demo feature from something that works in your environment.
Question 2: Can I track PII across backup history?
This one came from the compliance side of my brain. If Satori finds PII in a dataset, can I see that record existed across all my backups and track when it rolled off? Does this make responding to GDPR requests easier?
Yes. And they can remediate it too. They can redact sensitive data and still serve the cleaned version into downstream systems like RAG pipelines. So if you're feeding backup data into AI workflows, you can strip the PII and keep the utility.
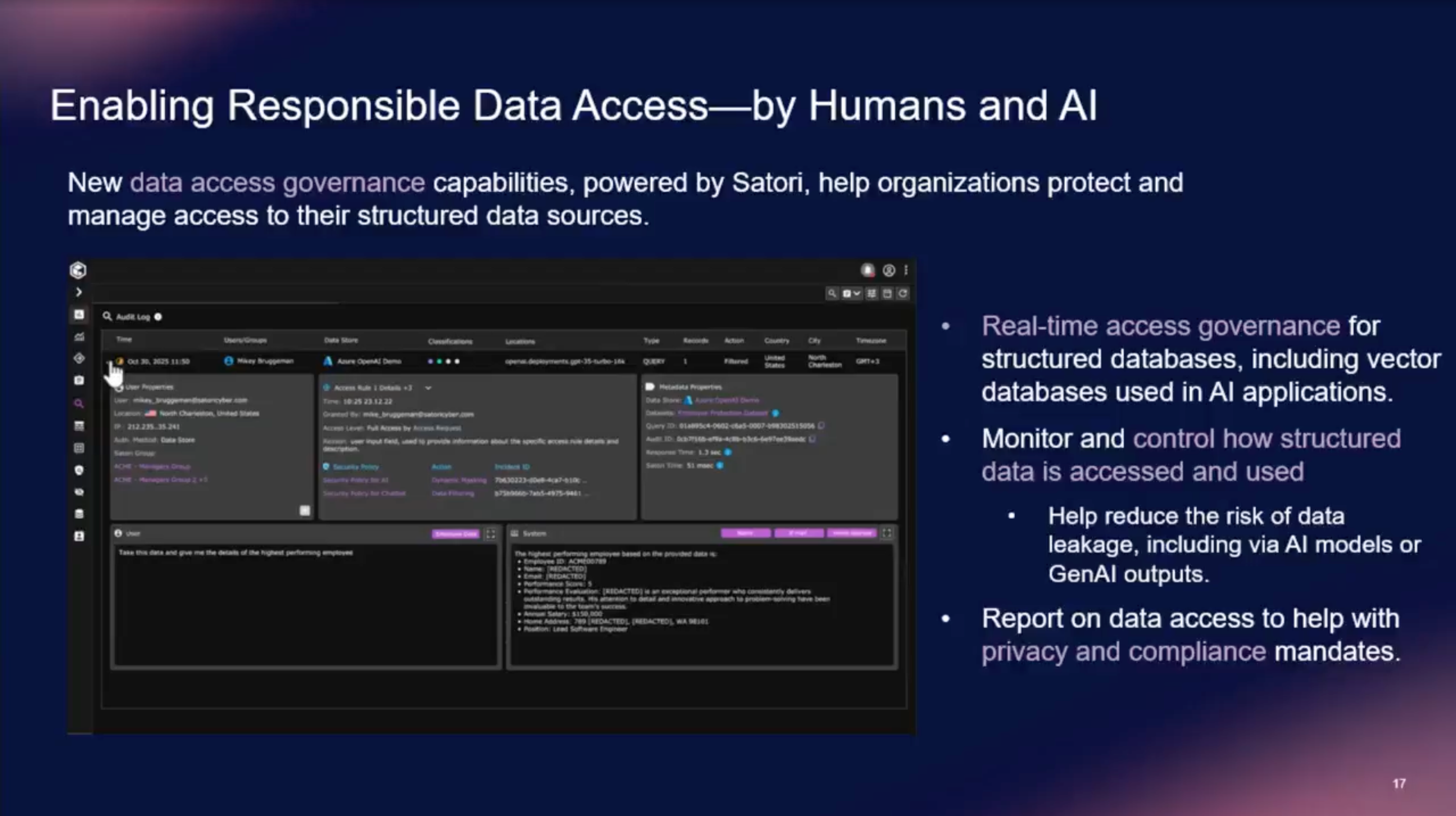
Satori's data access governance: a query hits an AI model, PII fields come back redacted in real time.
Let that sit for a second. In this newly agentified world, that has a ton of value for AI governance teams. That's a data governance capability, not a backup feature.
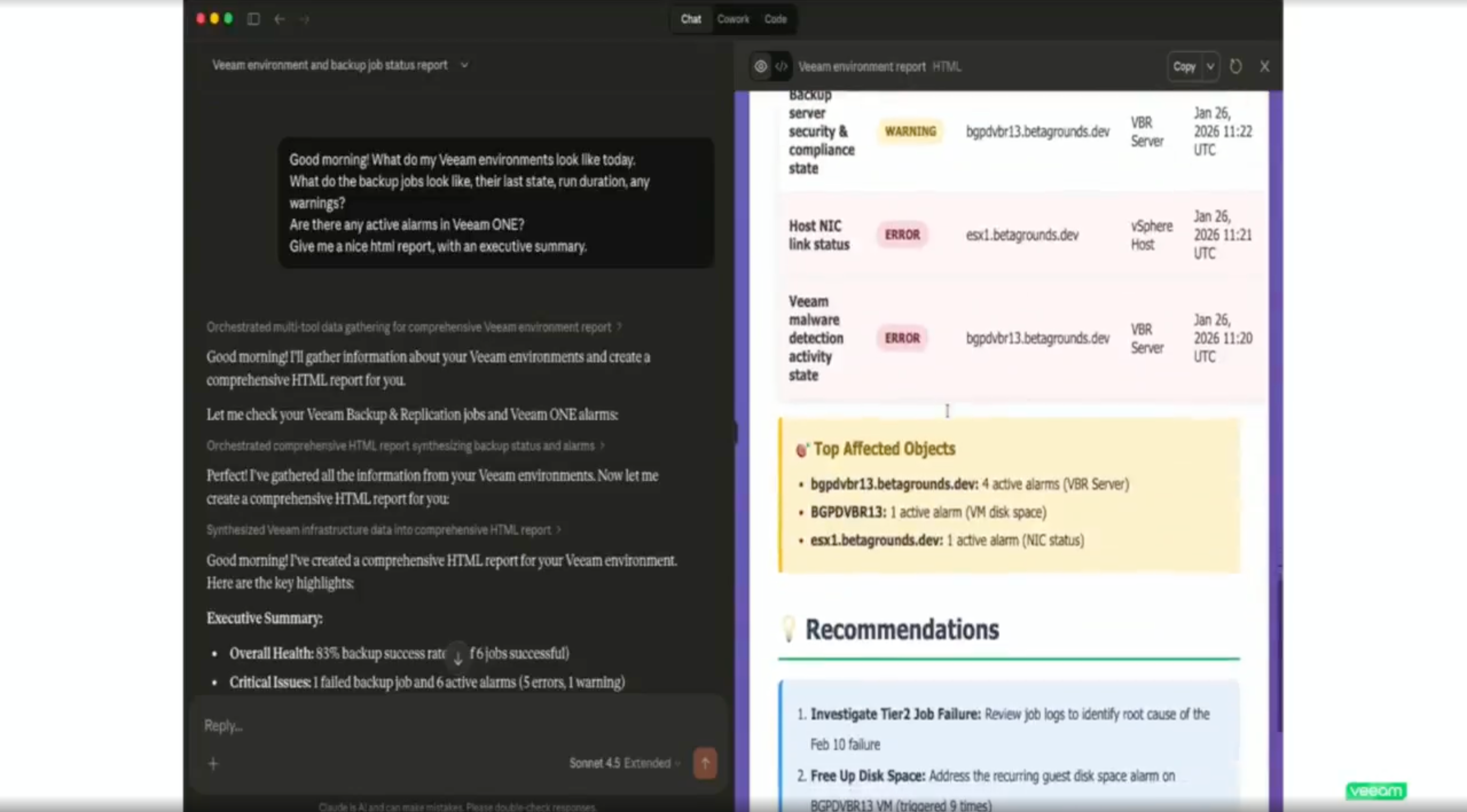
Question 3: Synthetic recovery, full VM or surgical file restore?
They demoed synthetic recovery, where the system automatically constructs a composite restore point from the last known clean version of every file across your backup history. I wanted to know if that was recovering the entire VM or surgically replacing files on the filesystem. And whether it was a downtime event.

How synthetic recovery works: clean files sourced from their last known good version across the backup timeline, infected and encrypted files quarantined.
It's a full system recovery. Point it at a system, it figures out which files need to be rolled back and which are clean, builds the composite, and recovers the whole thing. In the demo, they recovered to a clean room (isolated recovery environment) rather than straight to production, which lets you validate before you commit. You could go direct to production if you needed to.
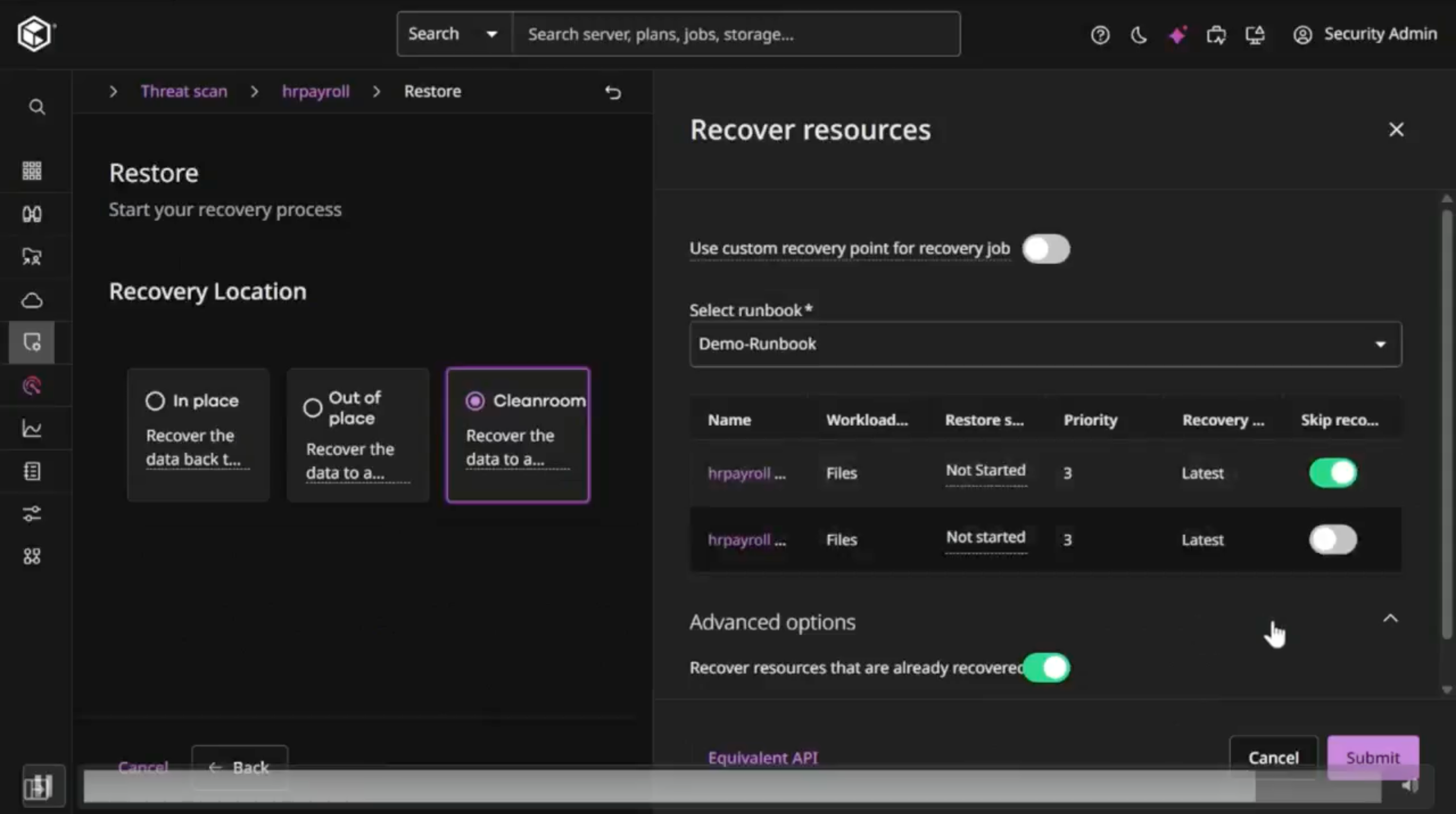
The actual recovery flow from the demo. Three destination options, with Cleanroom selected and a runbook configured for the restore.
That said, it was still a downtime hit to the system, which I was sad to hear. The stat they showed was something like 94.5% of files coming from the latest backup, with the remainder pulled from earlier clean versions. You see that breakdown before you hit the button.
The Bigger Picture: Backup Vendors Are Becoming Partners
Here's what I actually took away from this session.
Commvault is repositioning as a resilience platform that happens to be really good at backup, rather than a really good backup vendor that added some security tabs.
Consider what they showed in a single session: out-of-band threat scanning with YARA and hash hunting. DSPM across structured and unstructured data. Real-time data access governance sitting inline on AI pipelines. Identity resilience across AD, Entra, and now Okta. Bi-directional integrations with CrowdStrike, Microsoft Sentinel, and Security Copilot. Clean room recovery environments for validation before production. Automated runbooks that turn 200-step AD forest recovery into something repeatable.
The bi-directional signal sharing is what makes it feel real. Commvault generates threat signals from backup scanning, sends them to your SIEM/SOAR, and your security tools can trigger Commvault actions (forensic recovery, synthetic recovery, clean room spin-up) without leaving Sentinel or whatever platform your SOC lives in. That's actual integration, not a one-way export.
What I'm Still Watching
The session and demo were solid, but there's always a gap between conference demo and Tuesday afternoon in production.
A few things I'd want to dig into:
- Deep scan performance at real scale. They mentioned around 200 VMs in about 10 hours for deep scanning, with the hash-based hyper scanning being much faster. I'd want to see how that holds up with larger, messier environments.
- The Satori integration is new. How mature is the cross-platform policy engine in practice? Applying consistent data governance across Snowflake, Databricks, RDS, and legacy Oracle sounds great. I want to see it under load across a wide range of dataset sizes and technology maturity levels.
The 284-day recovery story is the one that stays with me. Not because it's dramatic, but because it's common. Organizations that can't verify clean recovery are rolling the dice every time they restore. The gap between "we have backups" and "we can recover cleanly and prove it" is where most of the risk actually lives.
Commvault is building into that gap. Whether they're the only ones doing it well is a longer conversation. But a backup vendor talking about YARA rules, DSPM, identity attack chains, and AI pipeline governance, and actually demoing it, tells you something about where this industry is headed.
Disaster recovery is not cyber recovery. It's not close. And the vendors who understand that distinction are the ones worth paying attention to.
The full Tech Field Day Extra session is available on YouTube. If you're thinking about cyber recovery, not just backup, it's worth the watch.